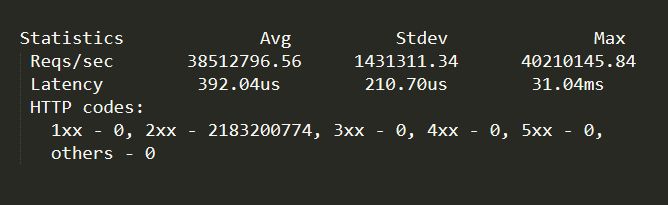
Holy crap that’s a lot of requests per second. 40 million per second, more than 2 billion in a minute, on the test hardware.
Have managed to make the back-end never hit the database for any reads except during start-up, and all database writes go through a WAL queue rather than directly to the database.
The requests are a mixture of request/response objects (which contain DTOs and collections of DTOs in the response) and media such as images and short videos. I don’t know how close we were to maxing out a dual 100gbit NIC — it is some exotic dual 100gbit NIC with four 25gbit ports on each NIC from my understanding, not sure on that as I haven’t physically seen the hardware with my own eyes. But there was still plenty of bandwidth to spare, and the quite a bit of CPU to spare too.
Now I will admit, these are synthetic tests, i.e. traffic replay of earlier live sessions, coming from another machine, without a bunch of network hardware in between, so I suspect real-world production usage will be considerably lower.
Configuration is:
MS SQL -> WAL cache -> Kestrel -> In-Memory Query & Object Cache -> NGINX -> Apache Traffic Server
Technically the Kestrel server application is doing its own in-memory/in-process object and object collection caching so that I am not dumbly relying on external caches to do the heavy lifting for me. The Kestrel server application is effectively just a cache filler once it gets going and has answered the initial burst of queries and built internal collections. And the only time Kestrel gets queried (after that initial burst) is if something hasn’t migrated to a more forward position (higher tier?) cache.
Update:
I have since moved from synthetic replay tests to production requests and our numbers ticked up a bit due to the way we shape our traffic so we’re just cresting 42M RPS, or around 2B+ per minute on a single machine.
I cannot go in to a lot of detail on implementation. But I am very happy with the throughput.
There’s still a little headroom, but I suspect I am going to be hitting limitations of the OS, network stack and drivers at that point.
I feed everything through eight separate 25Gbit connections, though tests have shown that I could get far better results by feeding through 32 x 10Gbit connections. Results better than “yeah, but 320Gbit is more than 200Gbit” would suggest. This would be due to packet offload, PCIe bandwidth, RAM <=> NIC DMA constraints, etc, etc.
The majestic monolith literally handles everything, from media to database to server. There are two other containers for logging and housekeeping.
I focused on what can I get out of the hardware. I optimized at each layer, which was the low-hanging fruit, then optimized the more esoteric parts, e.g. read-once/WAL database access pattern, automatically denormalizing data once it enters a caching layer, storing cached data in different data structures depending on its usage, deduplicating (but not normalizing) data where it made sense, updating in-memory cached objects on database writes, deferring all database writes to post-processed batches (housekeeping container), making the client smarter so that it didn’t ask for complex joins and other operations that couldn’t be cached, and so on. Not trusting the client, but assuming the client was smart.
There were a lot of bottlenecks that I was able to kick out by being given carte blanche to “fix it, I don’t care what it takes, make it so we can hit reddit numbers.” And then finally just tuning the hell out of the OS, the Mellanox cards, and so on.

